


Hi Techie's ,
In this blog, i will be discussing about what is monolith & micro services and why we use it.
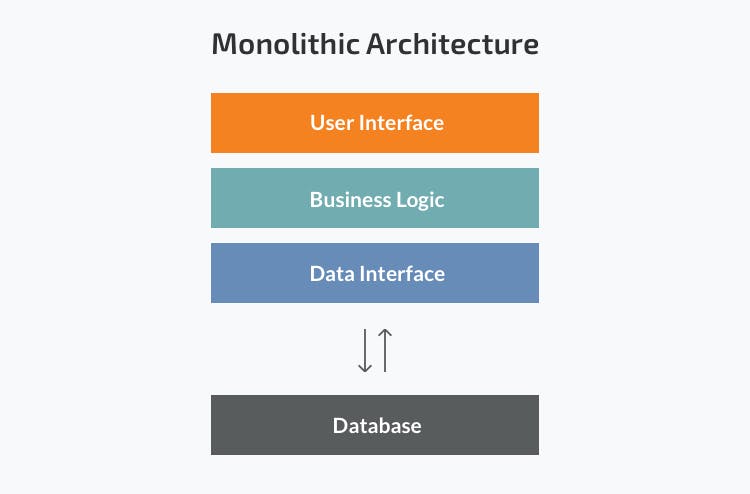
The Monolith
The Monolith is a single tier software application in which that user interface and data access code are combined into a single program from a single platform.
Some examples of Monolith are a single Java Jar file, which handles business logic for different areas of your project.
Pros :
- monolith is simple, especially for small projects.
- since everything is contained in a single code base that is no over engineering.
- It is also resource efficient at small scale.
Cons :
- modularity is hard to enforce.
- scaling is a challenge.
- monolith has all or nothing deployment because everything is contained in a single code base.
- monolith leads to long release cycles because over the time that single code base gets bigger.
Now let's talk about a very common misconception.
Can you use a API with a monolith?
Absolutely, api's has nothing to do with the monolith.
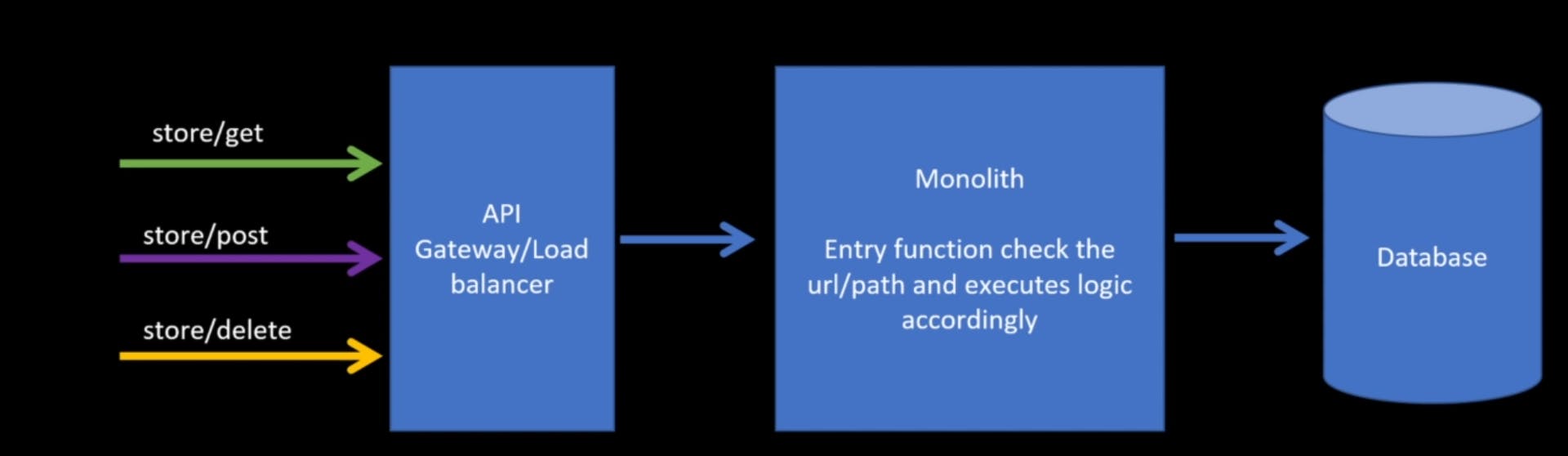
When different URL or paths hit this API gateways/load balancer, they could forward all these calls to the same monolith, and this monolith will have an entry functional path paragraph, which will check that you are are parh and invoke different functions within the monolith and executes the logic accordingly.
Now let's talk about the scaling of monolith.
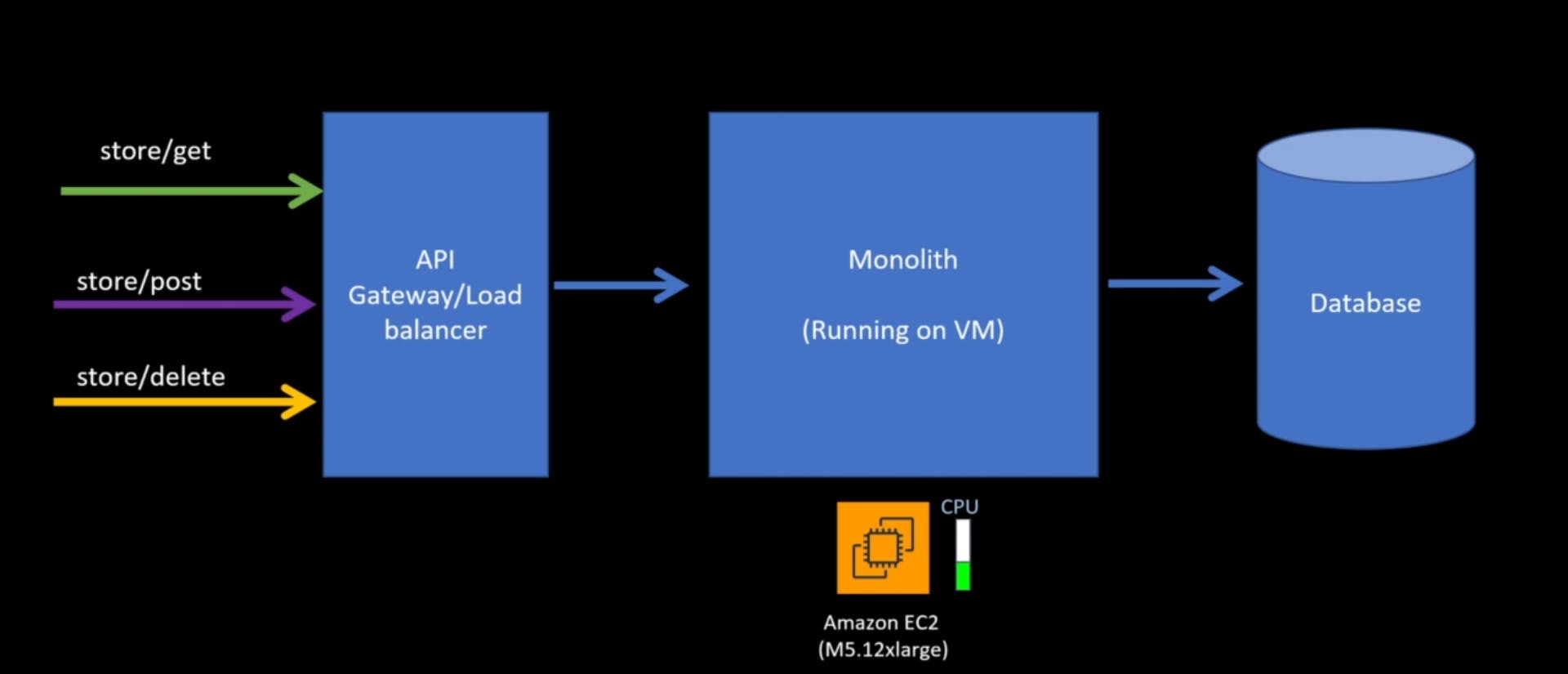
Let's say our monolith is running on virtual machine, and since you are running this huge program as one executable, you need a sizable, easy to install. In this example, this is it who is in m5.12x large, and we have these three different traffic patterns coming in for stores slash, get stored slash post and store slash delete.
So let's say the traffic for stores /get increases, so the CPU, as you can see, increased to a threshold limit.
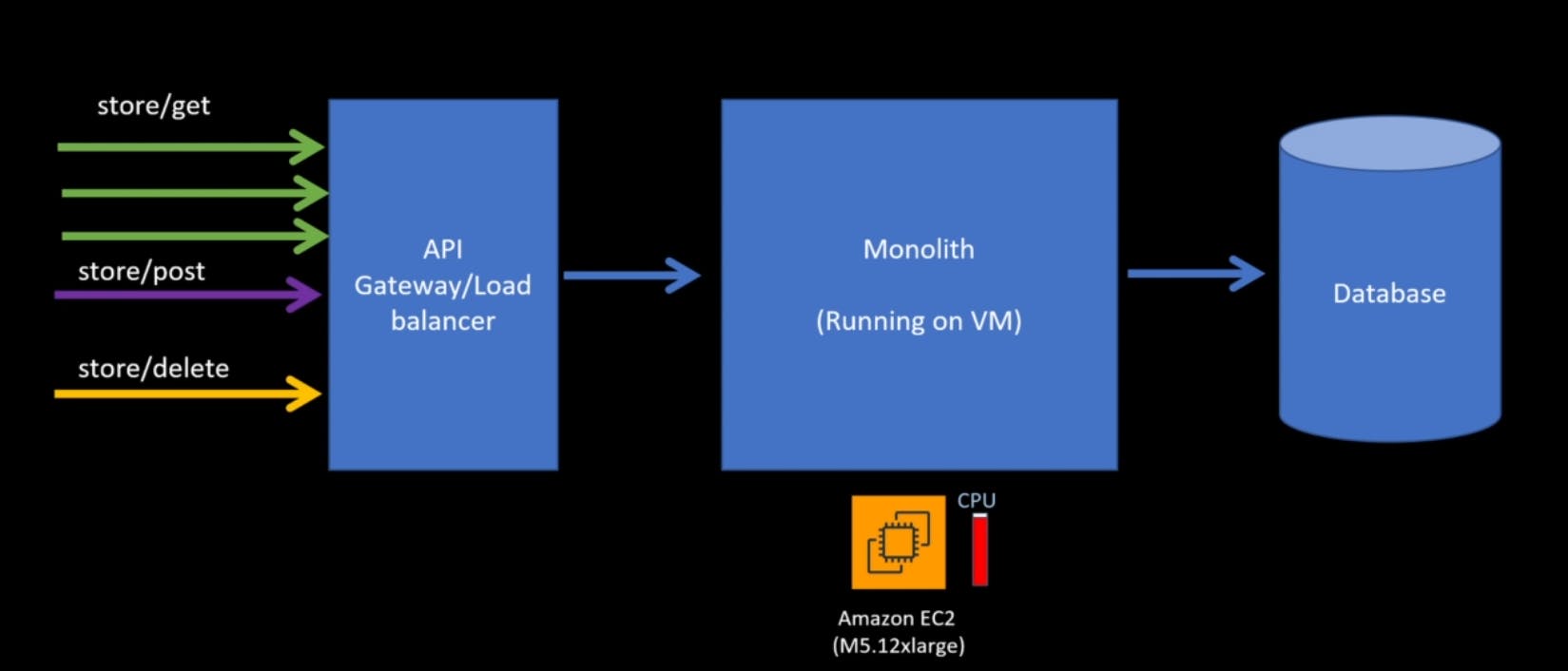 And if you have auto scaling group set for this virtual machine and the threshold for the larger scaling configuration exceeded which it is in this case.
And if you have auto scaling group set for this virtual machine and the threshold for the larger scaling configuration exceeded which it is in this case.
Instead of scaling just the CPU needed for the stores slash git component, you have to scale the entire monolith right because you cannot really pick apart different components to run on different tools with the monolith approach. So now we have 2 machines that large easy-to-use running and the CPU utilization for both of those went down.
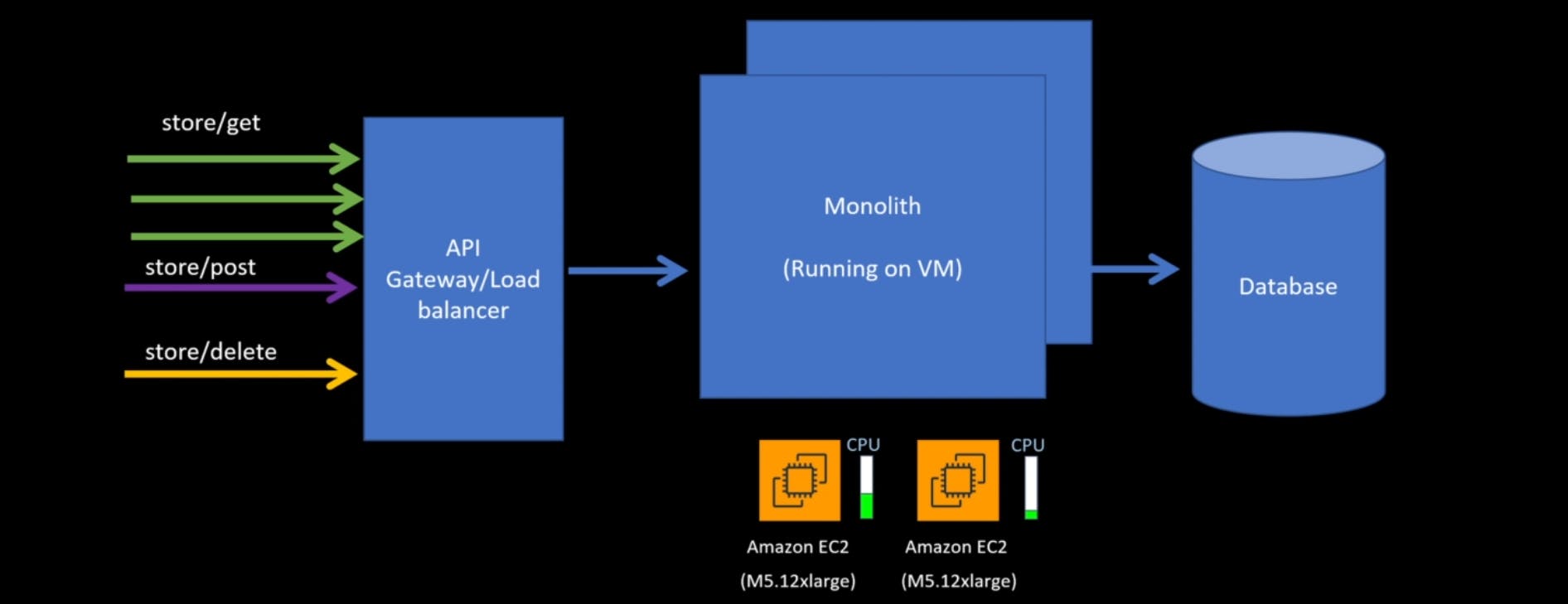
So even though you are using part of the CPU, you still pay full price for this to Amazon since, you have to assign a sizable virtual machine for monolith, so you end up paying a lot more.
So how would it look like with a microservices?
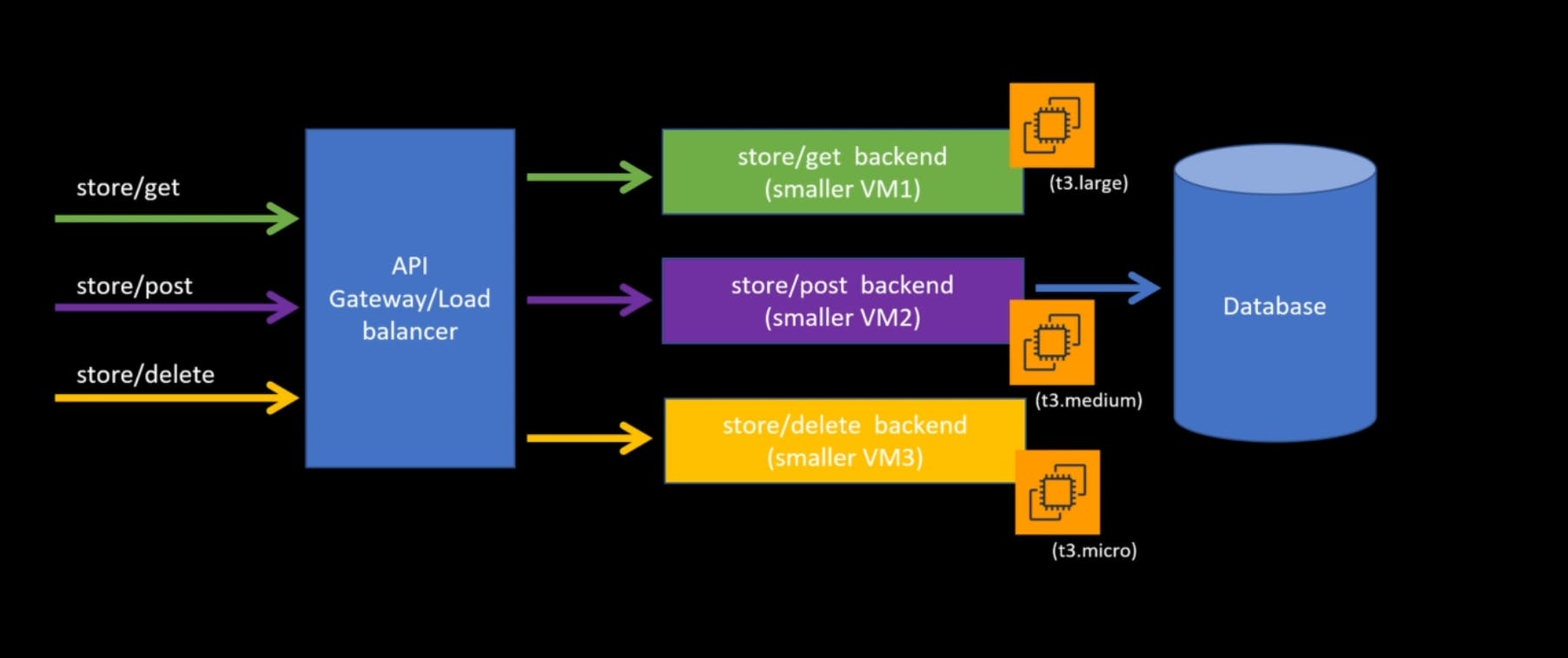
So the microservice, all the three components store /get stores, /post and store /delete have different code bases and on the backend you can see they are running on different virtual machines. And depending on the type of API, you can control the memory and CPU of the EC2. In this case, store /get back end is running in T3's, but large stores /post back end is running in T3.large, T3.medium and stores /delete back end is running on T3.Micro.
Now you might say Dev Valecha, this is not a right microservice because each microservice should have their own different database.
Alike :

Ideally, yes, but in real world scenario, it is not possible sometimes to break the big database into multiple small databases. so, we are going to talk about the characteristics of microservices, but remember that it is not all or nothing approach in real world enterprise projects.You fulfill some characteristics of microservices that makes your business agile and makes your life easier But it doesn't need to check all the boxes. So going back to our previous example, where our code base is separate and it is using the same database now lets a store slash get traffic increases instead of scaling up all the three different EC2 only the virtual machine that's running store /get backend needs to scale.
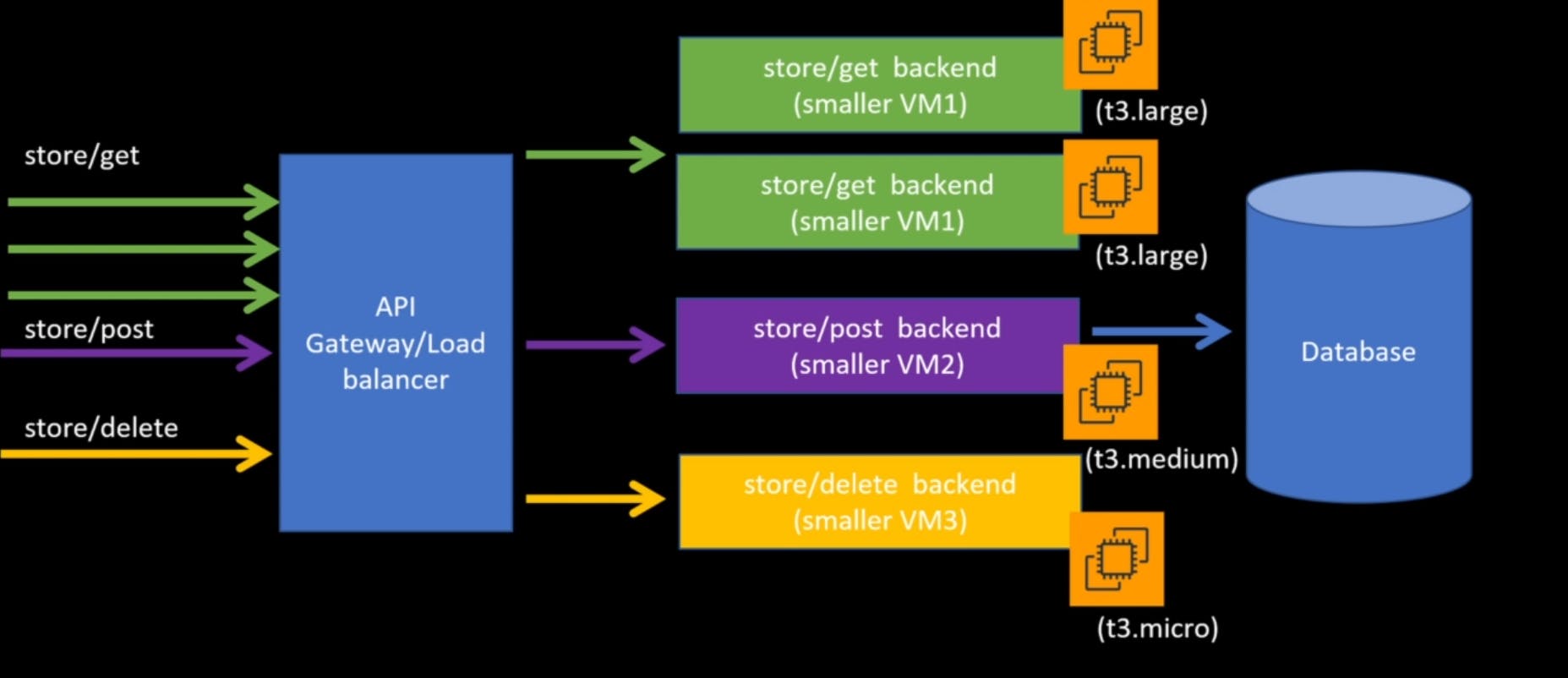
If you are using the single database for multiple microservices, you do need to keep in mind as the microservices scale, the database should be able to handle the increased connections. Generally, there are a lot of techniques to optimize the reading from the database, such as you can use replica caching, etc.. Another advantage of using microservices is since all these back ends are independent of each other and could be maintained by different teams. These microservices can be written in different programming languages. So, the store/get can be written in python. store/post can be written in nodejs. store/delete can be written in golang.
That is a fancy name for this feature.
polyglot
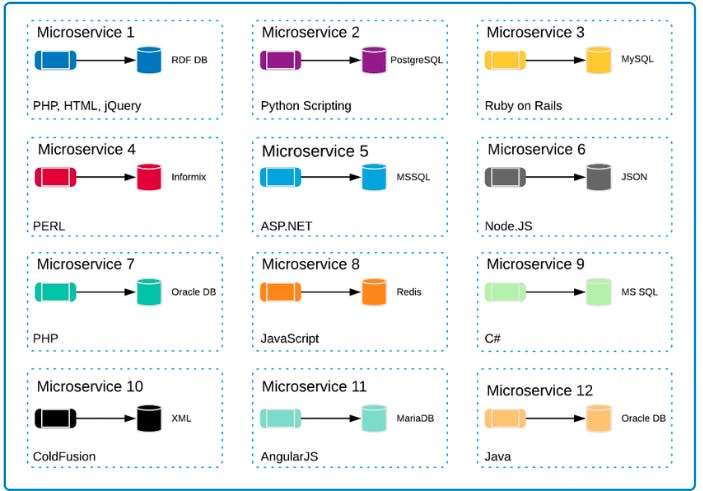
So what are the characteristics of Microservices architectures?
The core property is each microservice is independent of each other so each can scale irrespective of each other, as we saw since they are separate. You can apply different governance and security features, and you can deploy each of them independently. This makes your DevOps much faster and simpler because it is no longer an all or nothing approach.You can just deploy store /post back end without deploying store /s, delete or store last get. You can test this microservices independent of each other, and they should have different functionalities. And as I mentioned before, the important thing is it is not required to follow every characteristic. The main characteristic is independence scaling and independent functionality. However, like I mentioned, sometimes you will see the same databases being used for more than one microservices.
Thanks for reading this blog.
Keep writing amazing code.
Happy Hacking!
Happy Coding!
Please follow Dev for such amazing blogs.
